
秉承活到老学到老的原则,现在分享关于大数据和机器学习的课堂学习笔记,希望能帮到大家。
主要内容包括:
什么是大数据?
大数据实例分析:Twitter实时搜索
什么是机器学习?
机器学习实例分析:Shopittome.com
一、什么是大数据
大数据的历史由来已久,但“Big Data”这个词最早出现于1997年Oct ACM的一篇文章中,这是公认的“Big Data”的开始,而2001Feb Doug Laney的一篇划时代的论文,其为大数据定义了三个V被业界所认可,分别是:
Volume:绝对数量的增加
–受移动设备和社交网路普及的影响,数据量急剧增长
–同一数据存在多种拷贝
•Data in relational database for transactional use case
•Data in NoSQL for batch process
•Data in reverse index file for search
Velocity:产生速度
–数据正在以前所未有的速度产生和传播
–数据实时性的要求越来越高
Variety:形态
–结构化数据(Structured data): relational database, log, transactional data
–半结构化数据(Semi-structure data): chat, blog, tweet
–非结构化数据(Unstructured data): photo, audio, video
这所产生的最主要的挑战是可扩展性,具体来讲即算法的复杂度,无论是存储还是计算的复杂度和成本开销,如何是呈一种线性发展,甚至比线性还低。
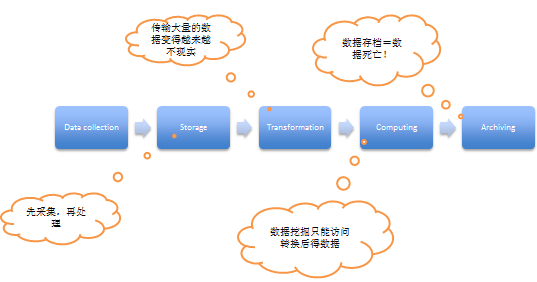
传统数据系统的局限:

1、先采集,再处理中间所产生的时间差已无法满足现实中实时处理的客观要求,比如热门微博实时推送;
2、巨大的数据量(Petabyte,Exabyte,Zettabyte)已让数据库之间的传输越来越不现实;
3、一般网站系统都是通过对现有的数据进行加工处理成相应的形式来进行分析,但是这个过程是不可逆的,当需要新的数据的时候,只能推倒重来再进行处理。
4、数据存档往往很少人会重新使用,数据存储=数据死亡。
针对传统数据系统局限,现阶段常见的解决方案:
–Transformation:数据转换
•连续的数据转换
•随数据量线性扩张: ~ O(n)
–Active archiving:数据存储
•混合计算和存储,计算的单元应当尽可能靠近存储的单元
•数据永远为计算准备好
–Exploring:数据挖掘
•同时访问原始数据和转换后数据
•可以进行增量计算,不需要等待全部数据齐备再进行计算
•机器学习:Machine learning
Cloudera 大数据的解决方案(采用hadoop):

1、省去采集点到转换点的传输,数据的计算和存储不再分家;
2、将只能访问变型后的数据改为统一用hadoop来储藏;
3、去掉原来数据仓储的概念,用hadoop来长期存储数据。
大数据的核心技术和产品:
•存储
–NoSQL: Cassandra, MongoDB, DynamoDB, HBase
–Cloud based large storage: Amazon S3
•消息
–Apache Kafka, RabbitMQ
•计算
–Hadoop, Apache spark, Storm
•机器学习 : Machine learning
–Weka
–Mahout
–MLbase
大数据的商业用途
•预测
–未来会发生什么
•实时分析
–现在正在发生的事件及趋势
•历史数据挖掘
–过去发生的事件及其原因
二、实时大数据分析实例: twitter

哈德逊河飞机迫降事件——意外事件的出现让更多用户在twitter 进行关键词搜索,但当时twitter并没有能力来及时地提供事件发生的搜索结果,而是一些其他的消息。后来twitter对其进行了改进,如上:
Search queries 进来后会首先进入Apache Kafka的消息流,而基于Storm流式计算框架(详情点击)的大数据存储处理系统会监听这个消息,将热门的消息带上标签送给AmazonMechanical Turk服务(人工服务),这里要通过一个基于历史数据的机器学习模型来进行判断关键词是否异常,如果异常则送到人工服务专家讨论版中,最后通过投票系统来确定并对twitter里面的相关信息来添加标签,方便用户搜索。在五分钟中内,突发事件的相关信息则会跳到搜索结果首版。
三、什么是机器学习
作为一套指导方法,机器学习构建一个智能系统,机器学习可以做到:
–基于历史数据自我调整
–基于历史数据预测未来
–根据规则进行最优化决策
–分析海量数据的内在规律
机器学习不能做到的:
•取代商业规则并取代第一步,但是机器可以学习帮助验证或优化商业规则
•取代人的智慧,但是机器可以学习帮助处理人脑力所不及的数据
•取代和客户的交互,但是机器可以学习帮助挖掘潜在的客户需求
机器学习的历史:

机器学习的基本构成:
主要构成:数据,模型,参数和误差公式
主要步骤:学习,预测,评估

机器学习的基本构成:

1、数据采集总的原则是越多越好;
2、不同模型对数据形态有一定要求,因此需要数据预处理;
3、数据可视化是为了让数据看上去更加直观,便于初步分析;
4、模型评估之后,如果不满意,可以将特征强化(修改特征参数),或者数据强化(修改数据范围等)。
机器学习的主要类型
如下图,这里无法确定具体解决什么问题,但是可以提供一些手段参考:

机器学习总的来讲分为两类学习:有指导的学习(提供机器数据,同时告知机器结果是否正确,从而让历史预测与模型得出的结果尽可能靠近,对于人来说,大体知道结果正确与否,但是需要机器来调整参数)和无指导的学习(只提供数据,但不知道结果是否正确)。
有指导的学习:
归类:通过大量的数据来提供二元的决策参考,对于多元问题,往往会简化成多个二元的问题,比如“红绿蓝”三元,会简化成三个二元的问题;
回归分析:确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
无指导的学习:
分组:比如说,给予一堆数据的采样,将其分为三类,但需要机器来提供一个最好的类别组合;
推荐:根据历史数据来分析并推送;
数据简化,降维:对于复杂的数据(每个数据有多个属性),将高阶的计算转化为低阶的计算。
每个机器学习类型可以解决的问题:
● 归类:

垃圾邮件——典型归类问题,根据历史数据来构造一个系统来进行邮件过滤。初始的时候没有数据,但是会鼓励用户来进行判断,从而学习垃圾邮件的特征。
Logistic regression (逻辑回归)——在预测对的时候,误差公式的“惩罚”是趋近于0,反之则趋近于无穷大,从而指导机器不断地去优化参数。具体参考这篇文章

Neural Network(人工神经网络)——一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式。
简单来讲,就如海浪一般,往前计算,往回来做误差分析,并进一步来进行参数优化,不断进行迭代调整,从而诞生一个网络般的计算模型。

● 回归分析:
比如一元线性回归,输入X 输出Y , 通过不同调整线的斜率,让总误差最小,从而为以后的预测来提供参考。

● 分组:
K-Means(分组算法:K平均算法)
如下图进行距离分类:随机分为两个中心点(事先假设为两类),然后再根据其他点到中心点的距离来分为两类,接下来将每一类的点再进行平均得到另外的中心点,之后再来根据其他点到中心点的距离来分为两类,之后再对每类的点进行平均找中心点,如此反复,直到中心点位置不变,则迭代结束。
这里要注意的是,最好中心点取在原有的点中,防止因为其中一个中心点太远而出现无法迭代的情况。
此外,由于K-Means 无法保证全局最优化,因此会选择不同的初始点来进行多轮分组,从而比较出一个尽可能最优的算法(类别内到中心点的距离最小)
因此,K-Means 是很费电脑CPU的。更多信息请参看这里。

Canopy(分组算法:蚊帐算法)
虽然这个算法比较粗糙,但是支持实时分类,弥补K-Means在数据处理速度上的不足。而当累积到足够的数据时,则可以回到K-Means继续优化分类。
其原理可以简单解释如下:(如下图)
1:给我一组存放在数组里面的数据D
2:给我两个距离阈值T1,T2,且T1>T2
3:随机取D中的一个数据d作为中心,并将d从D中移除
4:计算D中所有点到d的距离distance
5:将所有distance<T1的点都归如到d为中心的canopy1类中(注意哦,小于T2的也是小于T1的,所以也是归入到canopy1中的哦)
6:将所有distance<T2的点,都从D中移除
7:重复步骤4到6,直到D为空,形成多个canopy类
Canopy聚类经常被用作更加严格的聚类技术的初始步骤,像是K均值聚类。通过一个初始聚类,可以将更加耗费的距离度量的数量通过忽略初始canopies的点显著减少。

● 推荐:
Collaborative filtering(推荐算法:协调过滤)
下图是一个简单的协调过滤算法的例子,更多的可以参考这篇文章,图中所示的是针对某个商品在其他人打分的前提下,如何预测另外一个用户可能打的分数,如果预测出其打的分数比较低,则不会进行推荐。基本原理是先计算用户与其他用户的品味相似度,然后根据已打过分的最相似的N个用户的平均分值来进行预测。

Dimension Reduction(推荐算法:降阶算法)
如下图,每个用户都是4维的,即四阶数据,而每个产品也是这样甚至更多,这样对于运算来说是比较有压力的,这里我们可以将其改变为2维数据来进行代替,从而简化计算。这里通过矩阵运算(具体请Google),如下图的12.22和4.9在矩阵对角中所占的数字比重最大,则数学证明这足以浓缩了原矩阵的大部分数据,也就是说我们可以通过用用户和商品的矩阵数列中的头两个数据来代表这个用户和商品。

而当用户和商品可以用二维数据来进行表示的时候,我们就可以将其拉到一个二维平面上来进行分类和推荐,如下图。

机器学习实例分析:Shopittome.com
机器学习的商业应用
卖家
•用户需求动态
•欺诈识别
•智能广告投放
供应链和销售
•需求预测
•备货时间预测
•定价
•优化包装和递送
客户
•个性化搜索
•个性化推荐
•定向广告
•智能售后服务
Shopittome.com

这是个特卖推荐系统,其主要的工作和目标如下:
–用户注册,选择感兴趣的品牌,产品类别,个人信息等
–每天有新的特卖信息
–邮件推送,推荐最新的特卖
•目标: 如何把用户感兴趣的产品通过邮件推送给用户?
基本情况:
•用户量: 百万级别
•产品: 万级别
•全部计算:
–百万 x 万 = ~10亿
•时间要求:12 小时内
问题模型:推荐还是归类?
如果推荐的话,则有如下的问题:
–特卖周期很短,缺少用户反馈
–销售的产品变化很快,新产品不断出现,很难用历史的产品来预测新产品的属性。
因此选择归类的方法,原因如下:
–必须借助产品本身的属性和用户的品牌喜好数据
–核心的问题:喜欢,不喜欢?排序不是很重要
训练数据的准备:

规划:
•问题模型:归类
•目标设定:预测用户点击,是/否?
•训练数据:历史点击数据
•确定需要提取的特征
数据流程:

模型训练:

用老数据来对用户进行分组,用近期数据来进行核心的机器学习数据,用最新的数据来进行预测,并不断滚动到机器学习中。